协程Coroutine是一种轻量级的实现异步的方式,是代码执行的控制框架,是最新式的并发编程范式。它在使用上大大简化了以往多线程并发带来的种种麻烦(如状态同步和锁),最大的优势就是它是纯编程语言层面实现的,不受制于操作系统,因此它不会阻塞。在前两篇基础之上,今天再来深入的理解一下各种概念,并脱去协程华丽的外衣一探它的本质。

本篇为协程三步曲中的终篇:
- 初级篇:Kotlin进阶之协程从入门到放弃
- 高级篇:Kotlin进阶之协程从上车到起飞
- 终极篇:Kotlin进阶之协程从专家到出家
不过如此
协程是最新式的并发编程范式,所有文章都会大量的提及同步,异步,并发和并行等,需要先理解一下这些词语到底是什么意思。
什么是异步(Asynchronous)

在解释什么是协程之前,得先要理解什么是异步(Asynchronous)。异步也就是说程序是非同步的(Non synchronous),并不是按照顺序来执行的。这么说依然很绕,我们来一个简单的例子。比如有这样一个语句:
1 2 3 4 | |
这个代码的输出很明显是
1 2 | |
函数的执行是从上到下按我们写的顺序执行的,这就是顺序执行的意思,虽然说编译器会做一些指令重排以期对字节码进行一些优化,但有一个前提就是它不会改变程序的正确性,比如后面语句如果需要前面表达的结果时,一定能保证它们的执行顺序。同步的意思是,执行一个子函数,子函数会占用CPU,直到它运行结束再返回到调用它的函数,继续运行并能把结果带回给调用者,这即是同步的意思。比如这里的println,println没有执行完时,后面的语句是不会执行的。
异步的意思是函数语句的执行并不是按照我们写的顺序来运行的。比如说,前面的函数,如何能输出”Hello …world of Coroutine” ?这就需要让代码实现异步,非顺序的执行。有多种方式,协程就可以实现异步:
1 2 3 4 5 6 7 8 | |
什么是并发(Concurrency)
并发concurrency)就是代码同时开始运行,并发,并驾齐驱同时出发,英文是concurrent programming或concurrency,但出发了后是并行还是串行,并不管或者说不是重点。
异步是并发的前提,如果无法异步,那就不可能让代码同时开始运行,自然也就无法并发。并发是为了提高代码的运行响应效率或者说提升性能。
扩展阅读 并发(Concurrency)与并行(Parallelism)
什么是并行(Parallelism)
并行则是代码同时运行,任何时间段,都在同时运行。并行往往涉及复杂的计算任务,或者为解决计算量超级大的任务,需要借助专门的系统工具,把任务分解为不相关的子任务,然后分别运行在不同的计算机上面。所以大多数场景下,并行是并行计算(Parallel computing)的简称。除非专门从事于并行计算相关的工作,否则日常的软件开发基本上不涉及并行,大家平时接触最多的还是并发编程。
并发编程简史
随着软件的复杂度越来越高,以及多核心CPU的普及,让真并发变成了可能,导致并发编程已经变成了软件的一个非常基本的要求。现在,只要是软件,从Web到客户端,从商业软件到智能手机的App,甚至命令行工具也都需要并发,以提升性能和响应效率。从进程到线程再到协程,这其实是一部并发编程的历史。
进程(Processes)
是操作系统的概念,进程process)就是一个运行中的程序状态总和,包括代码和其所持有的资源。进程是操作系统管理运行中的程序的基本单元,未运行的程序不是进程,它只是一坨文件,当然了它可能会是其他进程持有的资源。
进程是最为原始的并发编程方式,不过严重依赖于操作系统,比如说创建,通信和同步都需要系统调用system call,如fork(),waitpid(),pipe(), socket()以及像semphore。进程虽然可以实现并发,但难以控制,可操控性太差,一般只作为粒度特别大的并发任务时,比如说上下游关系,不需要来回交互时,一个文本编辑器,需要打开一个HTTP超链接,可以启动浏览器,然后就跳转到浏览器了,啥时回来,回不回来都不重要,并不影响文本编辑器。
扩展阅读 如何理解:程序、进程、线程、并发、并行、高并发?。
线程(Threads)
线程thread)是更进一步的代码执行控制模式,它是轻量级的进程。每个进程至少由一个线程组成。线程是运行中的代码,它有自己的调用栈,是操作系统调度代码运行的最小单元。线程要依赖于操作系统的支持,比如pthread。每个线程要真实的运行在CPU上面,并且会独占CPU。现代的CPU都是有多个执行核心的,每个核心都可以跑一个线程,所以现代的CPU可以真实的让线程并行的运行。
线程是操作系统调度代码运行的最小单元,每个线程会独点一个CPU核心。当线程被调度到时,就会占有CPU,直到它运行完,或者被阻塞,一旦线程阻塞了,它就失去了CPU控制权,它的代码自然也就停止运行了,直到再次被操作系统调度得到CPU控制权,从阻塞状态再次回到运行状态。
从线程出现,一直到现在线程都是最为主要的并发编程方式,现在的软件效率都很高,服务器的高并发等等都是依赖于线程实现的。线程虽然较进程轻量,但仍依赖于操作系统,先是要操作系统支持线程,其调度也是依赖于操作系统的。线程也会占用不少的资源,它需要有自己的调用栈和CPU的上下文环境,只不过线程与线程能共享进程的资源而已,进程是程序运行和资源总和,运行其实都是由线程在控制。
协程(Coroutines)
技术在不断的演进,新式的并发实现方式也在不断的涌现,新一代的技术总是能解决上一代的问题,从而慢慢取而代之,就如线程之于进程。而新的挑战者,便是协程coroutine。
需要特别注意的是协程与线程没有关系,它是代码执行的操作框架,是实现异步和并发的最新的方式,它是让多个函数更好的协作以实现异步和并发。它是纯的编程语言层面的框架,不依赖于操作系统,因此它更为轻量,完全受开发者控制,与线程也没有关系,只会挂起,也就是某个协程停止执行,但不会阻塞线程,线程仍能去执行其他协程。相互协作的子例程,即为协程。
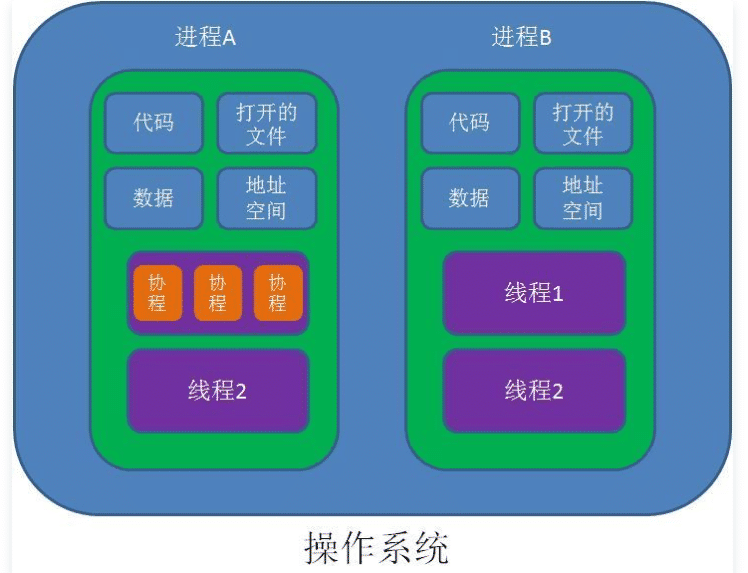
线程是操作系统调度代码运行的最小单元,所有的代码想要运行,必然要跑在某个线程里面,协程是代码运行的操作框架,所以协程自然也要跑在线程里面。或者说协程是更为轻量的线程,一个线程可以运行多个协程。
自上而下的来看,操作系统包含多个进程,每个进程有多个线程,而每个线程有多个协程。进程与进程之间共享操作系统提供的资源,如文件系统;进程分为程序的运行和资源,程序的运行就是线程(栈),资源就是堆内存;线程是代码的运行,其有独立的栈来存储自己的数据,包括执行中的代码和产生的本地数据,都在栈帧上面,此栈是操作系统中的代码栈,代表着CPU的运行,因此线程仍需操作系统支持,进程中的不同线程共享进程的堆内存,可以共享堆数据,当然也带来了麻烦;协程用来操作线程中代码运行的框架,是粒度更为小的代码的运行,但它并没有真实的栈,因此协程只是运行中的代码,并没有自己的数据,当然也可以共享堆内存。
脱去外衣看本质
我们来了解一下协程的基本原理,以更深刻的理解协程。
本质是状态机+跳转
前面说过协程是代码运行的控制框架,一个协程可以挂起,其他协程得以继续执行,如果不是因为操作系统在调度,在编程语言层面,这其实就是从一处代码跳转到了另一处代码。因此,协程的核心原理是代码的跳转。如何跳,跳到哪,又是由状态机确定的(或者叫做『事件驱动模式』)。看大Python就明白了,Python中协程其实叫async I/O。
想像有一个巨大的switch/when语句,遇到某个条件时会执行函数A(协程A),它改变条件后break(挂起了),条件变了会进入不同的分支,执行另一个函数B(协程B),协程B仍可以改变条件,再回到原来的分支去执行函数A(协程A继续执行了)。
除了switch/when,还可以用如goto/longjmp之类的语句实现跳转。
有栈(Stackful)和无栈(Stackless)
有两种协程的实现方式,一种称之为有栈的Stackful,另一种则是无栈Stackless。
- Stackfullness的意思是指可以在当前代码的调用栈(可能是非协程)中挂起,恢复的时候能在挂起的地方继续执行,所有的函数栈都还在。
- Stackless的意思是挂起只能发生在协程中。
什么意思呢,我们来理解一下,如果可挂起的函数只能运行在协程中或者被其他可挂起的函数调用,那么就是stackless的,意思就是说可挂起的函数必须是协程里面的顶层函数,那么协程启动之前的栈对于协程来说都是不可见的。就比如Kotlin就是stackless的,因为suspend函数只能由协程调用或者另一个suspend调,它不能在常规的调用栈中,必须为它启动一个协程。
Stackful需要每个协程开辟额外的空间来保存直到挂起点的stack,但它可以实现一些非常复杂的功能,相当于supsend与非suspend可以混着用,随时挂起,继续执行的时候原先的函数栈都还在,当然了这么实现起来代价肯定也是要大一些的。而stackless虽然限制多一些,只能由协程调用一个supsend函数,但效率高啊,实现起来也稍微简单。
扩展阅读:
- How do stackless coroutines differ from stackful coroutines?
- What are the Stackless and Stackful Coroutines?
- Stackless vs. Stackful Coroutines
- Which of coroutines (goroutines and kotlin coroutines) are faster?
CPS(Continuation Passing Style)
CPS(Continuation Passing Style)续体传递风格,是一种函数式的编程风格,函数并不直接返回结果,而是接收一个代码块作为最后一个参数。这个代码块会在函数要执行完被调用执行,用以处理函数结果。其实这个代码块就是回调函数,称之为续体(Continuation),它会决定程序接下来的行为。整个程序就通过一个一个的Continuation拼接在一起。

如果以同步式的写法,函数处理foo的返回值,可这样写:
1 2 3 4 | |
如果改成CPS式,就是酱婶儿的:
1 2 3 4 5 6 7 8 9 10 | |
只有到了挂起点才会挂起
需要注意的是,协程的代码并不是随时挂起,只有遇到了挂起点才会挂起。什么是挂起点呢?就是执行到了被suspend修饰的函数时,就会被挂起。协程是编程语言自己实现的代码执行控制框架,所以对于协程的实现者来说决定在哪里挂起是可控的。
扩展阅读:
协程是如何实现的
下面看一下协程在Kotlin的内部机制,以了解一下Kotlin是如何实现协程的。这里并不是为了深究它的好与坏,了解底层的知识都是为了更好的运用上层知识。另外要注意,这部分为了厘清概念用的都是伪码,并不是完全可运行的代码。
Kotlin协程的内部实现
借助CPS和状态机就可以实现协程,在Kotlin中就是这么做的。我们通过一个简单的例子就能把它的原理讲清楚。
前面讲了CPS是把函数调用后续操作封装成为一个代码块,传给调用的函数,其会在函数体最后执行此代码块。代码块就是针对 结果操作的一坨代码,为了更加通用,可以声明一个接口,作为续体的类型。在Kotlin中,这便是接口Continuation:
1 2 3 4 5 | |
创建一个实现了此接口的对象就可以当作续体传递给另一个函数。当遇到被suspend修饰的函数时,Kotlin的编译器就会生成一个继体对象,此对象会持有suspend函数运行相关的状态,如内部函数的返回值,以及状态机的状态。同时生成一个状态机函数,状态机接收续体对象作为参数,根根据其状态标签,执行不同的内部suspend函数,并把续体继续当作参数传给其他的suspend函数,直到退出。
举个🌰,对于酱紫的suspend函数:
1 2 3 4 5 6 7 | |
里面会有两个挂起点,把函数体分成三部分,所以可以视为一个三个状态的状态机:
1 2 3 4 5 6 7 8 9 10 | |
最终会生成续体对象,续体包含挂起点之后代码继续运行的所有必要参数,以及状态机函数,大概会是酱婶儿的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
这里的原理并不复杂,我们捋一捋就能弄懂了:状态机函数,就是一个大的when语句。初始状态是没有续体的,创建一个续体对象,并执行第一部分代码,直到挂起点,修改续体到状态2,然后执行suspending函数,此时便挂起了,也就是说其实函数已执行完了。当挂起结束后,继续运行时,就回调续体里面的resume,仔细看resume又会回到状态机,只不过这时状态已在挂起前改为2了,所以会执行第2部分的代码。同理修改状态为3,然后再次挂起,等继续时就会执行到第3部分代码,这时没有挂起点了,所以不再传入续体,整体协程结束了。
厘清后,发现协程的实现非常的巧妙:挂起点把函数分为不同部分,用状态区分,用when执行不同的部分;挂起前把状态改为下一部分,然后把状态机函数当成续体,传给挂起点的suspending函数,当挂起结束后执行续体,便又回到状态机,但会进入新的状态,执行余下部分的代码。就这样,一次执行一部分代码,直到没有挂起点了,不再传入续体了,原suspending函数也就结束了。
扩展阅读
其他编程语言的协程
比较值得学习就是Go语言的协程Goroutines,Go语言是比较早且比较完整的支持协程的编程语言,并且它的协程是stackful的。
扩展阅读:
以及大Python中的async I/O。
扩展阅读:
- Async IO in Python: A Complete Walkthrough
- INTRODUCTION TO ASYNCIO (ASYNCHRONOUS IO) IN PYTHON
- An introduction to asynchronous programming in Python with Async IO
测试Testing
这里主要指的是针对开发人猿的单元测试,而非测试同学的验收测试。
协程是一种并发编程范式,因此,测试与并发代码测试是一样的。无论哪种测试,本质都是一样的,把代码当成黑盒,给特定的输入,看是否能产生符合预期的输出。特定的输入通常需要Mock。
需要测试的是逻辑
一定要厘清,逻辑代码是需要测试的,要把重点放在逻辑的测试,啥是逻辑?其实就是条件控制语句和循环语句,所以要盯着条件和循环来写case。
比如说,网络请求,要把无网络,连接超时,服务器返回超时,返回码不对,返回数据格式不对,这些情况都Mock到,以测试逻辑是否有把所有的可能情况都考虑到了。
TestScope
Kotlin的协程库特意准备了一个专门用于测试的TestScope,这个scope的好处在于它使用的是虚拟时间。时间对于并发编程是特别重要的,比如经常需要等待多少时间间隔(协程相互协作的等待,或者等待服务器返回),以及异步任务的超时时间,在实际的运行中肯定是真实的去等。但对于测试代码来说,也这样真的去等,就有点难以接受了,单元测试的一个非常重要的要求就是测试必须要快,要能快速反馈结果。
为此,就有了TestScope,它用的是虚拟时间,可以理解为这个scope中delay的时间是一个虚拟的时间,它会很快的执行,相当于这里的时间变快了。因为它相当于是整体的时间都变快了,所以里面代码相对的时序并不受影响,所以不会影响原本应该有的时序。可以理解为仙界,仙界一天地界一年。
扩展阅读 Testing coroutines。
并发安全性(Concurrent safety)
这里指的是并发程序中共享数据的并发安全性(Concurrent safety),而非数据隐私安全的那个安全(data security)。
线程有自己的代码,但却可以与其他线程共享数据,代码操作数据,看到的数据不一致,就产生了并发安全问题,并发安全问题是由多线程共享变量(shared mutable data)引发的,所以要想解决并发安全,要么别共享变量(无论是使用常量Immutable data,避免共享变量,用线程自己的变量ThreadLocal,用锁来保证共享变量的原子访问);要么别用多线程。
协程也是并发编程,如果协程切换了不同的运行线程,且又访问了共享数据,那就有可能有并发安全。注意并发安全问题(共享可变数据不一致)是由多线程引起的,如果没有切换线程,则没有问题,我们可以验证一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
这个示例中多个协程共享了一个变量,并且++并不是原子的,但结果是对的,说明没有发生数据不一致的问题,原因是没有为协程切换线程。我们切一下线程试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
这回可以看到数据不一致的问题发生了,因为结果并不是预期的1000。
想要减少并发安全问题,可以多多使用常量(Immutable data),此外如果必须要共享变量,那么可以用协程专用的互斥锁。注意,线程专用的原子化数据结构如AtomicInteger等也是可以使用的,并且效率很高,但只能用于一些有限的数据结构如如基础类型或者集合;其他的线程同步方式如synchronized/ReentrantLock/CountDownLatch等会阻塞线程,会严重影响性能,毕竟它们是为多线程并发准备的工具,在协程中并不推荐使用。
轻量级锁
协程专用的互斥锁(Mutual exclusion)是Mutex,它是轻量级的锁,原因就是它只会挂起,而非阻塞。可以用它来保护对共享变量的操作,以解决并发一致性问题。它的使用方法与Java中的ReentrantLock是一样的,可以用lock/unlock式,或者try-lock-finally-unlock式,或者更为方便的扩展函数withLock {…},比如酱婶儿的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
和用withLock,是一样一样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
要保护共享变量的操作而非协程
需要特别注意,协程是异步代码,不能以同步思维来看待。我们用锁是来保护协程内部对共享变量的操作,防止数据不一致,因此要把锁放在共享变量操作的地方(critical section)。妄图大范围的对整个协程加锁是没有用的,比如酱紫:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
这里失效的原因与异常捕获是一样的,协程并不是同步代码(not synchronous),它是异步的(asynchronous),外围的try/catch和lock之类的操作对异步代码是没有效用的。
扩展阅读
书籍推荐
《七周七并发模型》 这本书是专门讲并发的,并且讲了多种语言的并发模式,是理解并发非常好的书籍,值得精读。